GenAI en modelos de riesgo de crédito: evidencia técnica vs. narrativa de mercado
En los últimos meses, la conversación sobre inteligencia artificial generativa (GenAI) en crédito digital ha estado marcada por una expectativa clara: su potencial para transformar —o incluso reemplazar— los modelos tradicionales de scoring.
Sin embargo, al analizar evidencia técnica reciente, el panorama es considerablemente más matizado. Un estudio desarrollado por CRIF (2025) realiza una comparación estructurada entre modelos tradicionales de riesgo y diferentes configuraciones basadas en GenAI, evaluando no solo desempeño predictivo, sino también estabilidad, calibración y fairness.
1. GenAI como modelo de scoring: limitaciones estructurales
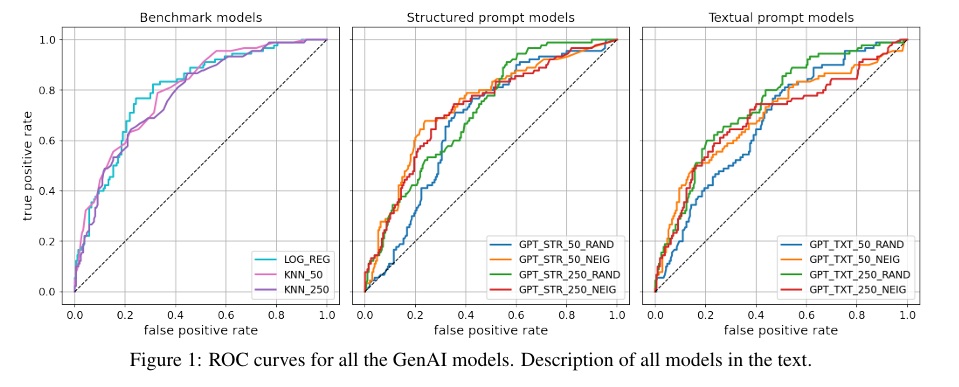
El estudio construye modelos GenAI utilizando esquemas de few-shot prompting, donde cada cliente es representado mediante variables estructuradas (tipo JSON) o descripciones textuales. A partir de estos inputs, el modelo genera clasificaciones binarias de riesgo y estima probabilidades mediante técnicas como logprobs.
Sin embargo, este enfoque enfrenta una limitación crítica: la imposibilidad de escalar en volumen de datos como lo hacen los modelos tradicionales. La dependencia del contexto (tokens), la selección de ejemplos y la consistencia del prompt limitan su capacidad de generalización.
2. El rol del “example selection”: paralelo con KNN
Un punto particularmente relevante es la estrategia de selección de ejemplos para alimentar el modelo generativo. El estudio evalúa tanto selección aleatoria como selección basada en cercanía (similar a KNN).
El resultado es contundente: incluso utilizando ejemplos cercanos, los modelos GenAI no logran superar ni siquiera un promedio simple de los vecinos. Esto sugiere que, aun optimizando el contexto, no alcanzan la eficiencia de modelos estadísticos básicos.
3. Evaluación robusta: más allá del accuracy
La evaluación incorpora métricas clave utilizadas en riesgo de crédito:
- Gini coefficient
- KS statistic
- Log Loss
- Brier Score
Adicionalmente, se incluyen métricas de fairness como Equalized Odds Difference (EOD) y BRIO, lo que permite analizar no solo el desempeño, sino también el comportamiento frente a variables sensibles como edad, género o condición migratoria.
4. Fairness: señales interesantes, pero no concluyentes
Los modelos GenAI muestran ligeras mejoras en algunas métricas de sesgo, especialmente en términos agregados. Sin embargo, los resultados no son consistentes entre variables, lo que indica que aún no existe una estrategia clara ni robusta en este frente.
5. Implicación clave: arquitectura híbrida
La principal conclusión no es si GenAI funciona o no, sino dónde genera valor. El estudio sugiere un enfoque híbrido donde:
- GenAI potencia la captura y transformación de datos
- Los modelos tradicionales mantienen el rol central en la predicción
Esto abre oportunidades claras en procesos como lectura de documentos, estructuración de información y generación de variables.
6. Implicaciones para crédito digital en Latinoamérica
En mercados emergentes, donde la calidad de datos es heterogénea y la explicabilidad es crítica, intentar reemplazar modelos tradicionales con GenAI puede introducir más riesgo que valor.
Una estrategia más sólida consiste en fortalecer los inputs, mejorar la calidad de datos y construir arquitecturas donde cada componente cumpla un rol específico dentro del ciclo de crédito.
Documento completo
A continuación puedes consultar el estudio completo:
Conclusión
Más allá del hype, este tipo de análisis permite aterrizar decisiones tecnológicas con evidencia. La conversación no debería centrarse en si usar o no GenAI, sino en cómo integrarla correctamente dentro del ciclo de crédito.
En Technovation continuamos evaluando este tipo de investigaciones para traducirlas en arquitecturas reales, aplicables y sostenibles para el ecosistema de crédito digital en Latinoamérica.